
Apache Fury (现已经改名为 Fory) 是一个由 JIT 动态编译与零拷贝能力驱动的多语言序列化框架,提供 Java、Python、Golang、JavaScript、Rust、C++ 多语言 SDK。它支持多语言对象自动序列化,在性能上相比 JDK 序列化最高可提升 170 倍。
Fury 仓库 GitHub 地址:https://github.com/apache/fury

背景
序列化是系统通信的基础组件,广泛用于大数据、AI 框架、云原生等分布式系统。进程间、语言间、节点间的数据传输,以及对象持久化、状态读写与复制,都离不开序列化。序列化的性能与易用性,直接影响系统的运行效率与开发效率。
像 Protobuf、FlatBuffers 这类静态序列化框架,无法直接用于跨语言应用开发,因为它们不支持共享引用与多态,并且需要提前生成代码。
而 JDK serialization、Kryo、Fst、Hessian、Pickle 这类动态序列化框架虽有易用性和动态性,但不支持跨语言,同时还存在明显的性能瓶颈,不适合高吞吐、低时延、大规模数据传输场景。
因此,我们开发并开源了全新的多语言序列化框架 Apache Fury(https://github.com/apache/fury)。借助**高度优化的序列化基础能力、JIT 动态编译与零拷贝技术,Fury 同时具备高性能与高易用性,可自动完成任意对象的跨语言序列化**,并提供极致性能。
什么是 Apache Fury?
Apache Fury 是一个由 JIT 动态编译与零拷贝驱动的多语言序列化框架,兼具超高性能与易用性:
- 多语言支持:Java、Python、C++、Golang、JavaScript、Rust,并且可轻松扩展到更多语言。
- 高度优化的序列化基础能力。
- 零拷贝:支持 out-of-band 序列化与 off-heap 读写。
- 高性能:以异步多线程方式在运行时使用 JIT 生成序列化代码,可优化方法内联、代码缓存、死代码消除、哈希查找、元信息写入与内存读写。
- 多协议设计:同时具备动态序列化的灵活性与静态序列化的跨语言能力。
- Java Serialization:
- 可直接替换 JDK、Kryo、Hessian。无需改动用户代码,最高可获得 170 倍性能提升,显著提升 RPC、数据传输与对象持久化效率。
- 100% 兼容 JDK,原生支持
writeObject、readObject、writeReplace、readResolve、readObjectNoData等 JDK 自定义序列化方法。
- 跨语言对象图序列化:
- 自动跨语言序列化任意对象,不需要 IDL、Schema 编译或对象/协议转换代码。
- 跨语言序列化共享引用/循环引用,避免数据重复与递归错误。
- 支持对象多态,可同时序列化多个子类型对象。
- 行式格式(Row format)
- 面向缓存友好的二进制随机访问格式,支持跳过反序列化与惰性反序列化,适用于高性能计算与大规模数据传输。
- 支持自动转换为 Apache Arrow。
- Java Serialization:
核心序列化能力
虽然不同场景需要不同协议,但序列化底层操作高度相似。
因此,Fury 定义并实现了一套基础序列化能力,用于快速构建新的多语言序列化协议,并通过 JIT 加速与其他优化获得统一性能收益。
同时,任何一个协议在基础能力层面的优化,也会反哺其他协议。
序列化基础能力(Serialization Primitives)
常见序列化操作包括:
- Bitmap 操作
- 数值编码与解码
- int/long 压缩
- 字符串创建与拷贝
- 字符串编码:ASCII、UTF8、UTF16
- 内存拷贝
- 数组拷贝与压缩
- 元信息编码、压缩与缓存
Fury 在各语言中使用 SIMD 等高级能力,将这些基础操作做到极致高效。
零拷贝序列化
在大规模数据传输中,对象图里通常包含多个二进制缓冲区。某些序列化框架会把这些二进制数据写入中间缓冲区,带来多次高成本内存拷贝。Fury 借鉴 pickle5、Ray 与 Apache Arrow,实现了 out-of-band 序列化协议,可捕获对象图中的全部二进制缓冲区,避免这些中间拷贝。
下图展示了零拷贝序列化流程:
当前 Fury 支持以下零拷贝类型:
- Java:所有基础类型数组、
ByteBuffer、ArrowRecordBatch、VectorSchemaRoot - Python:array 模块的所有数组、numpy 数组、
pyarrow.Table、pyarrow.RecordBatch - Golang:byte slice
你也可以基于 Fury 接口扩展新的零拷贝类型。
JIT 动态编译加速
自定义类型对象通常携带大量类型信息。Fury 利用这些信息在运行时生成高效序列化代码,将大量运行时操作前移到动态编译阶段。通过更充分的方法内联、更优代码缓存、减少虚函数调用、条件分支、哈希查找、元信息写入与内存读写,序列化性能可大幅提升。
在 Java 里,Fury 实现了运行时代码生成框架,并定义了算子表达式 IR。随后,Fury 基于运行时对象的泛型信息做类型推断,构建描述序列化逻辑的表达式树。
代码生成框架会从表达式树生成高效 Java 代码,再交给 Janino 编译为字节码,并加载到用户 ClassLoader 或 Fury 创建的 ClassLoader 中,最终由 Java JIT 编译为高效机器码。
由于 JVM JIT 会跳过过大的方法编译与内联,Fury 还实现了优化器,可递归拆分大方法为小方法,确保代码尽可能被编译并内联。
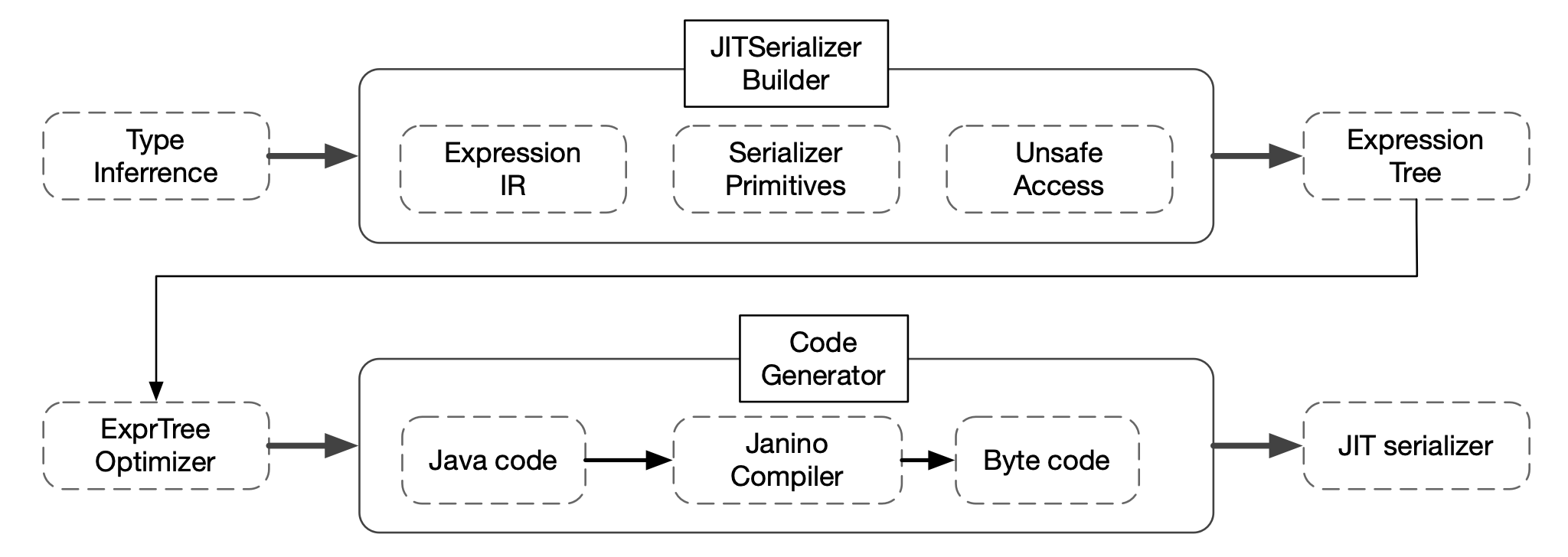
Fury 还支持异步多线程编译:在后台线程池执行代码生成任务,在 JIT 完成前使用解释模式,避免序列化抖动,用户无需专门做对象预热序列化。
Python 与 JavaScript 的 codegen 思路类似。直接生成源码也更利于开发调试与问题排查。
由于序列化需要深度操作各语言对象,而语言本身通常不暴露内存模型底层 API,native 方法调用成本也较高,所以无法直接用 LLVM 构建统一的序列化 JIT 框架。为此,我们在每种语言中分别实现了专用 codegen 框架。
静态代码生成
虽然 JIT 能显著提升序列化效率,并基于运行时数据分布生成更优代码,但像 C++ 这类语言没有反射、没有虚拟机,也缺少内存模型底层 API,无法通过 JIT 动态生成序列化代码。
在这类场景中,Fury 正在实现 AOT codegen 框架:根据对象 Schema 静态生成序列化代码,并通过生成的序列化器自动处理对象。对于 Rust,则通过 Rust 宏静态生成代码。
缓存优化
在序列化自定义类型时,Fury 会对字段进行重排序,让同类型字段连续写入,以更好命中数据缓存与 CPU 指令缓存。
基础类型字段会按字节大小降序写入。这样在起始地址对齐时,后续读写操作也更可能落在内存对齐位置,CPU 执行效率更高。
多协议设计与实现
基于 Fury core 提供的多语言序列化能力,我们已经构建了三类协议,分别面向不同场景:
- Java serialization:面向纯 Java 序列化场景,最高可获得 170 倍性能提升;
- 跨语言对象图序列化:面向应用开发导向的多语言编程与高性能跨语言序列化;
- 行式格式序列化:面向 Apache Spark、Apache Flink、Apache Doris、Velox 等分布式计算引擎与特性框架。
后续我们还会为更多核心场景新增协议。用户也可以基于 Fury 的序列化框架构建自己的协议。
Java 序列化
Java 广泛用于大数据、云原生、微服务与企业应用。因此 Fury 在 Java 序列化上做了大量优化,可显著降低系统时延和服务器成本,并明显提升吞吐。实现亮点如下:
- 超高性能:基于 Java 类型体系、JIT 编译与 Unsafe 底层操作,Fury 相比 JDK 最高快 170 倍,相比 Kryo/Hessian 最高快 50~110 倍。
- 100% 兼容 JDK serialization API:原生支持全部 JDK 自定义序列化方法
writeObject、readObject、writeReplace、readResolve、readObjectNoData,确保各种场景下的序列化正确性。Kryo 与 Hessian 在这类场景存在一定正确性问题。 - 类型兼容性:即使序列化端和反序列化端的类 Schema 不一致,也可正确反序列化。支持应用升级部署时独立增删字段。Fury 的类型兼容模式相比类型一致模式几乎无性能损失。
- 元信息共享:在同一上下文(如 TCP 连接)下跨多次序列化共享元信息(类名、字段名与字段类型等)。首次序列化时发送元信息,对端据此重建反序列化器;后续序列化可跳过重复元信息传输,降低网络流量并自动支持类型兼容。
- 零拷贝支持:支持 out-of-band 零拷贝与 off-heap 内存读写。
跨语言对象图序列化
Fury 的跨语言对象图序列化主要面向高动态性与高易用性场景。
尽管 Protobuf、FlatBuffers 等框架支持跨语言序列化,但仍存在明显限制:
- 需要预定义 IDL 并静态生成代码,动态性与灵活性不足;
- 生成类不符合面向对象设计,无法附加业务行为,不适合作为跨语言应用开发中的领域对象;
- 不支持多态。面向对象编程通常通过接口调用子类方法,但这类框架支持有限。FlatBuffers 虽有
Union,Protobuf 虽有OneOf/Any,但 API 在序列化与反序列化过程中都要显式判断对象类型,实质上不是真正的多态; - 不支持循环引用与共享引用。用户需为领域对象单独定义一套 IDL,自行实现引用解析,并在各语言里编写领域对象与协议对象之间的转换代码。对象图越深,代码越复杂。
针对以上问题,Fury 实现了跨语言对象图序列化协议,支持:
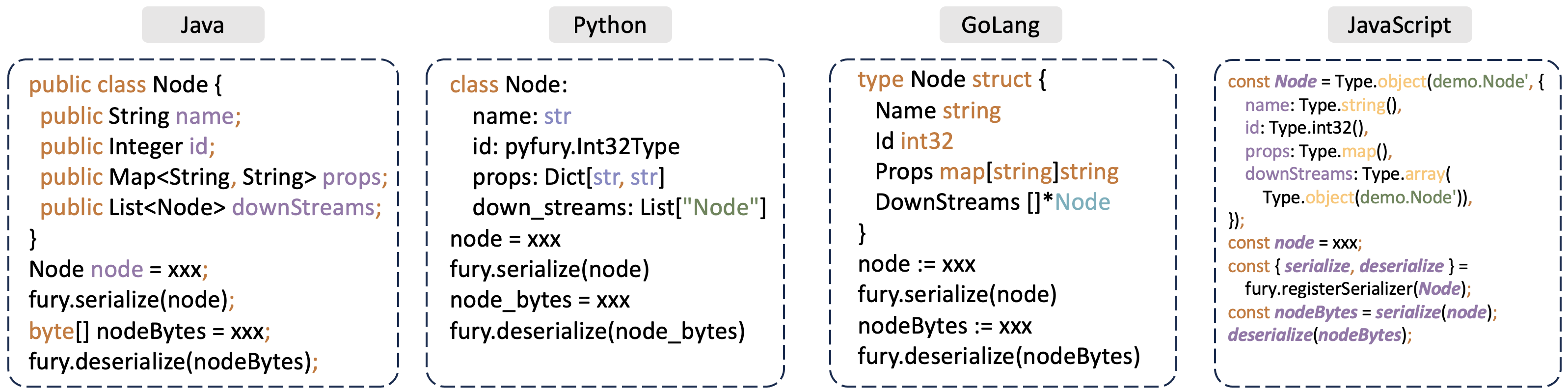
- 自动跨多语言序列化任意对象:只需在序列化端与反序列化端定义类,无需创建 IDL、无需 Schema 编译生成代码、无需编写转换逻辑,即可把一种语言的对象自动序列化为另一种语言对象。
- 自动跨语言序列化共享引用与循环引用。
- 支持对象多态,符合面向对象编程范式,可自动反序列化多个子类型对象,无需手工干预。
- 同时支持 out-of-band 零拷贝。
自动跨语言序列化示例:
行式格式(Row-format)
在高性能计算与大规模数据传输场景中,数据序列化与传输往往是系统的性能瓶颈。若用户只需读取部分字段,或按对象某些字段过滤数据,完整反序列化会产生大量无谓开销。因此,Fury 提供了一种二进制数据结构,可在二进制数据上直接读写,避免序列化/反序列化开销。
Apache Arrow 是标准化列式存储格式,支持二进制读写。但列式格式并不适用于所有场景。在线与流式计算中的数据天然按行组织,而列式引擎在涉及数据更新、Hash/Join/Aggregation 操作时也会使用行格式。
然而当前并无统一行格式标准。Spark/Flink/Doris/Velox 等计算引擎都定义了各自行格式,不支持跨语言且仅供内部使用。FlatBuffers 虽支持惰性反序列化,但要求静态编译 Schema IDL 且需手动管理偏移量,难以应对复杂场景。
因此,Fury 参考 Spark Tungsten 与 Apache Arrow format,实现了二进制行式格式,支持随机访问与局部反序列化。目前 Java/Python/C++ 版本均已实现,可直接在二进制数据上读写以规避全部序列化开销,并支持自动转换为 Arrow 格式。
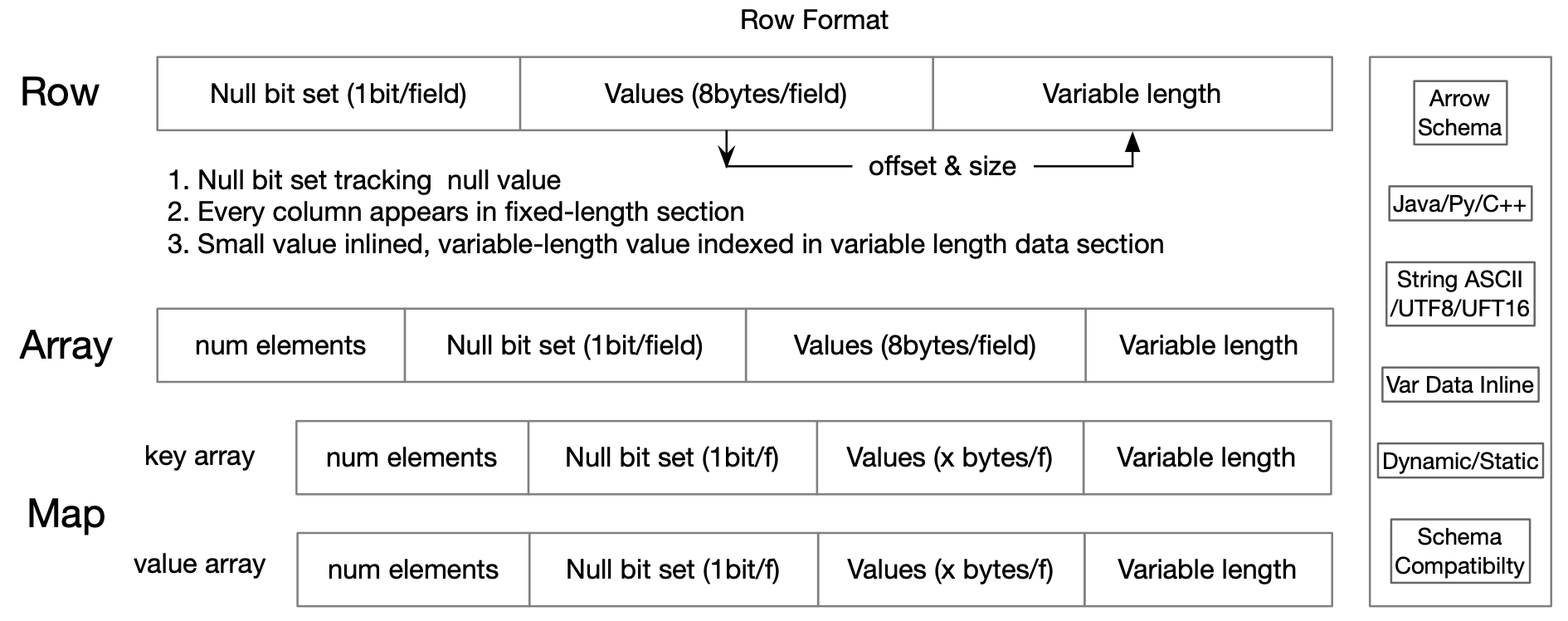
这种格式采用紧凑存储、字节对齐且缓存友好,可显著加速读写。通过避免反序列化,还能降低 Java GC 压力与 Python 运行开销。针对 Python 的动态特性,Fury 数据结构实现了 getattr、getitem、slice 等特殊方法,保证其行为与 Python dataclass、list、object 一致,用户几乎无感知。
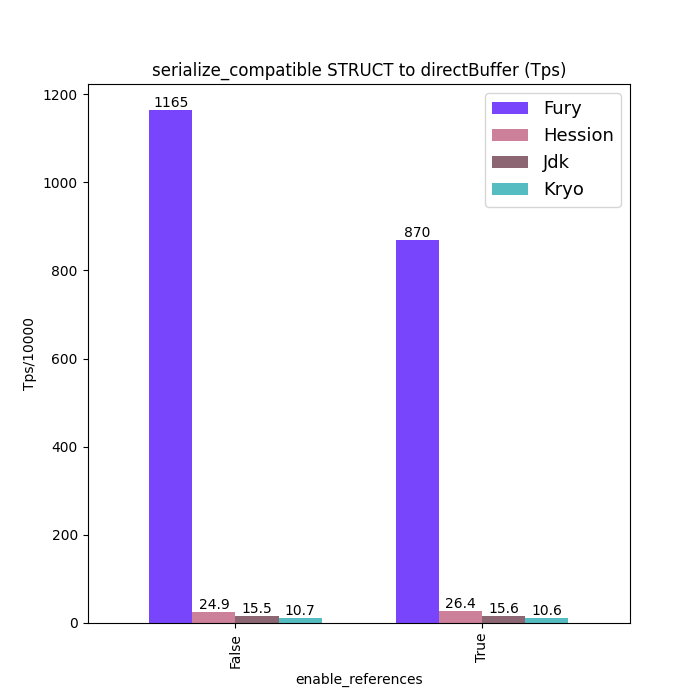
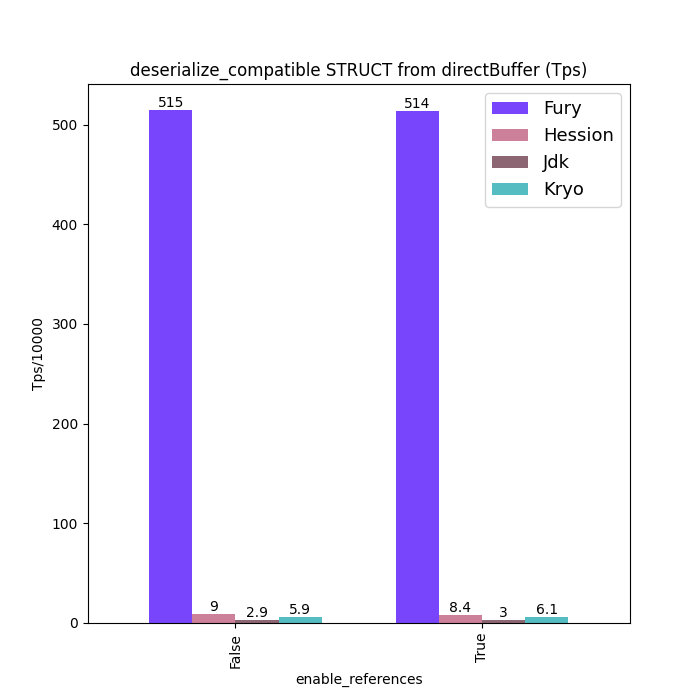
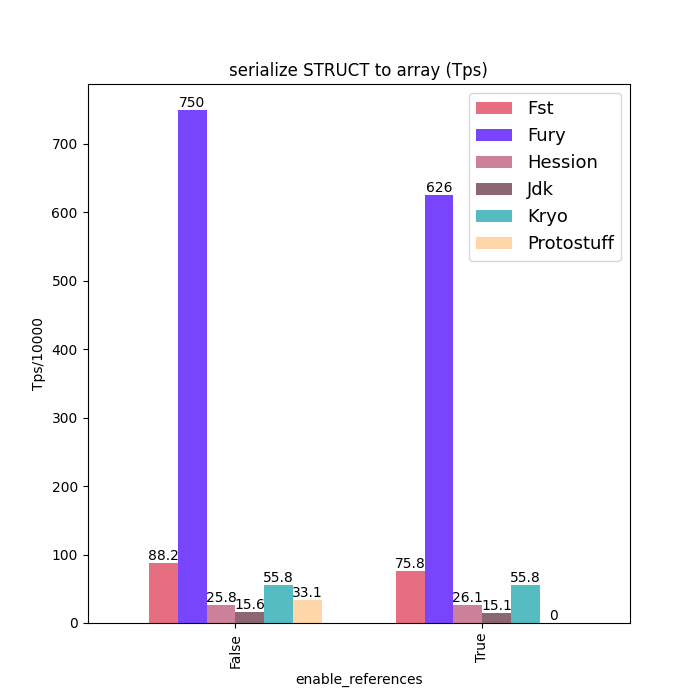
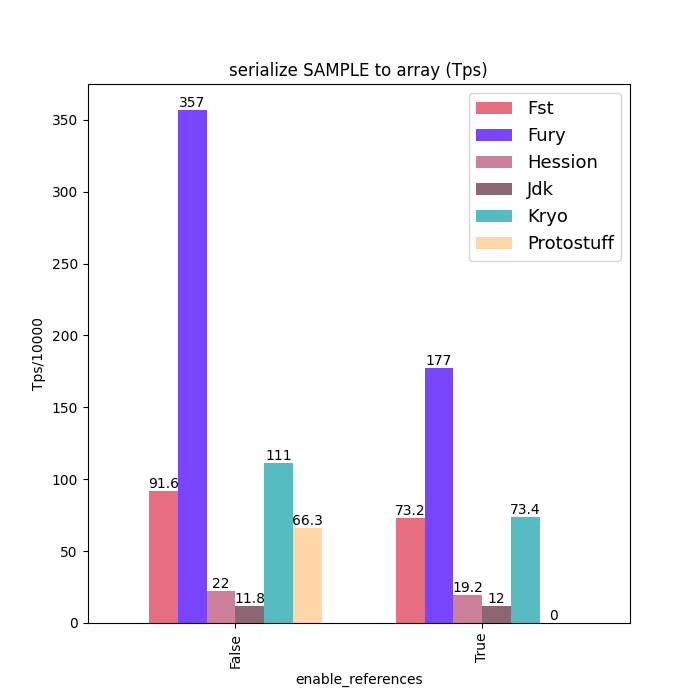
性能对比
下面给出一些 Java 序列化性能数据:标题中含 “compatible” 的图表示类型兼容模式(支持前向/后向兼容)下的数据;标题中不含 “compatible” 的图表示无类型兼容模式(要求序列化端和反序列化端类 Schema 完全一致)。
为保证公平,测试中对所有框架都关闭了零拷贝特性。
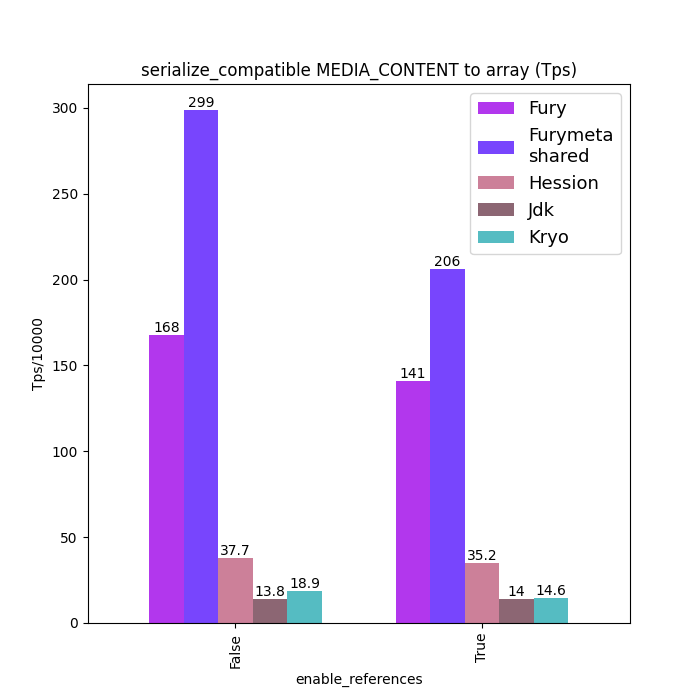
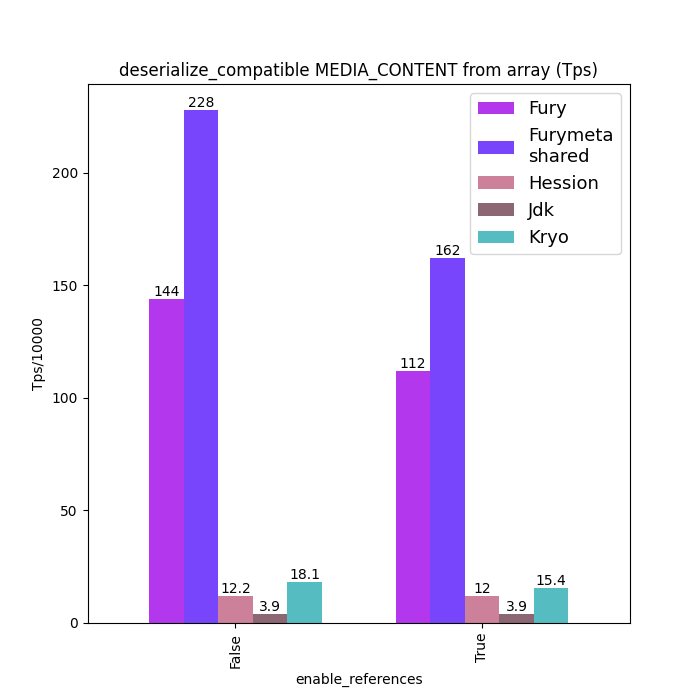
路线图
- 元信息压缩、自动元信息共享与跨语言 Schema 兼容
- 为 C++ 与 Golang 提供 AOT Framework 静态代码生成
- 为 C++ 与 Rust 增加对象图序列化支持
- 为 Golang、Rust、NodeJS 增加行式格式支持
- 支持 Protobuf 兼容
- 增加面向特征与知识图谱序列化的协议
- 持续完善序列化基础设施,支撑更多新协议
欢迎加入
我们致力于把 Apache Fury 打造成开放、中立、鼓励热情与创新的社区项目。社区内开发与讨论全程开源透明,欢迎任何形式参与,包括但不限于提问、代码贡献、技术讨论等。
期待收到你的想法与反馈,一起推动项目持续演进,打造更好的序列化框架。
Fury 仓库 GitHub 地址:https://github.com/apache/fury
欢迎提交 Issue、PR 和 Discussion。