
TL;DR:Apache Fory C++ 是一个极致性能的跨语言序列化框架,在 二进制性能 上表现出色,同时支持 多态类型、循环引用、Schema 演进,并可与 Java、Python、Go、Rust、JavaScript 无缝互操作。全程基于现代 C++17,零运行时反射开销。
- 🐙 GitHub: https://github.com/apache/fory
- 📚 文档: https://fory.apache.org/docs/guide/cpp
C++ 序列化的核心痛点
凡是在多语言环境里做过工程落地的 C++ 开发者,最终都会遇到同一堵墙:现有方案通常让你做艰难取舍。
- IDL 优先框架(Protocol Buffers、FlatBuffers):需要先定义并编译 Schema,原生 C++ 类型表达能力会被压缩,集成摩擦也很明显。每次类型变更,都要多语言代码同步再生成。
- 基于反射的框架(Boost.Serialization、cereal):跨语言支持有限,对循环引用和多态的支持薄弱,往往要写大量样板代码。单语言内好用,一跨系统边界就容易失效。
- 手写二进制格式:速度快,但脆弱。Schema 一变就可能出现静默损坏,新类型还要手工补编解码逻辑。
Apache Fory C++ 打破了这种取舍:它在性能上可与顶级 C++ 序列化库竞争,同时原生支持多态、共享/循环引用、Schema 演进,并通过简洁的 C++17 API 实现与 Java、Python、Go、Rust、JavaScript 的 二进制兼容。
Apache Fory C++ 为什么不一样?
编译期代码生成
很多序列化框架为了灵活性,会在运行时付出代价:每次调用都要借助虚函数分派或哈希表查询类型信息。Apache Fory 走了另一条路:通过 FORY_STRUCT 宏和 C++ 模板元编程,在编译期直接生成序列化逻辑。最终得到的是可内联、类型特化的代码,没有虚函数分派、没有反射、没有额外运行时开销:
#include "fory/serialization/fory.h"
using namespace fory::serialization;
struct Person {
std::string name;
int32_t age;
std::vector<std::string> hobbies;
std::map<std::string, std::string> metadata;
std::optional<std::string> nickname;
};
FORY_STRUCT(Person, name, age, hobbies, metadata, nickname);
这一个宏就能生成编译期字段元信息、基于 ADL(Argument-Dependent Lookup,实参相关查找)的高效序列化/反序列化代码,以及类型注册钩子。你既可以把宏放在 class 内访问 private 字段,也可以放在 namespace 作用域里支持第三方类型。
跨语言二进制协议
Apache Fory C++ 与 Java、Python、Go、Rust、JavaScript 使用相同的二进制编码格式。你可以在 C++ 里序列化 struct,在 Python 里直接反序列化——无需适配层、无需 Schema 转换、无需版本协商。对于不同语言团队协作的微服务架构,这一点尤其关键:
// C++:序列化
auto fory = Fory::builder().xlang(true).build();
fory.register_struct<Person>(100);
auto bytes = fory.serialize(person).value();
# Python:反序列化(同一二进制格式,同一 type ID)
fory = pyfory.Fory(xlang=True)
fory.register(Person, type_id=100) # 与 C++ 使用同一 ID
person = fory.deserialize(data)
要实现可靠的跨语言互操作,核心前提是:参与运行时之间使用一致的类型 ID/名称、一致的规范字段名,以及兼容的同名字段类型。
通过智能指针实现多态
在 C++ 中序列化多态对象一直很棘手。多数框架要么手工做类型标记,要么生成大量样板代码。Apache Fory 会自动处理:它通过 std::is_polymorphic<T> 检测多态类型,并借助 std::shared_ptr / std::unique_ptr 保留完整运行时类型身份。比如反序列化一个实际持有 Dog 的 shared_ptr<Animal>,你拿回来的仍然是 Dog:
struct Animal { virtual ~Animal() = default; int32_t age = 0; };
FORY_STRUCT(Animal, age);
struct Dog : Animal { std::string breed; };
FORY_STRUCT(Dog, FORY_BASE(Animal), breed);
struct Cat : Animal { std::string color; };
FORY_STRUCT(Cat, FORY_BASE(Animal), color);
struct Shelter { std::vector<std::shared_ptr<Animal>> animals; };
FORY_STRUCT(Shelter, animals);
auto fory = Fory::builder().track_ref(true).build();
fory.register_struct<Shelter>(10); fory.register_struct<Dog>(11); fory.register_struct<Cat>(12);
Shelter s;
s.animals.push_back(std::make_shared<Dog>()); // 运行时类型是 Dog
s.animals.push_back(std::make_shared<Cat>()); // 运行时类型是 Cat
auto decoded = fory.deserialize<Shelter>(fory.serialize(s).value()).value();
assert(dynamic_cast<Dog*>(decoded.animals[0].get()) != nullptr); // 运行时类型被正确保留!
Fory 同样支持用于独占所有权多态字段的 std::unique_ptr,以及智能指针集合(如 std::vector<std::shared_ptr<Base>>、std::map<K, std::unique_ptr<Base>>)。
共享/循环引用跟踪
真实世界的数据模型里,共享对象和循环结构很常见:父节点指向子节点,子节点再回指父节点;多个订单共享同一个客户对象。传统序列化框架往往要么重复写入(浪费空间),要么遇到循环就直接栈溢出。
开启 track_ref(true) 后,Fory 会在整个对象图范围内跟踪对象身份:共享对象只序列化一次,后续引用编码为回溯引用;循环也会自然终止:
struct Node {
virtual ~Node() = default;
int32_t id = 0;
std::vector<std::shared_ptr<Node>> neighbors;
};
FORY_STRUCT(Node, id, neighbors);
auto fory = Fory::builder().track_ref(true).build();
fory.register_struct<Node>(200);
auto node1 = std::make_shared<Node>(); node1->id = 1;
auto node2 = std::make_shared<Node>(); node2->id = 2;
node1->neighbors.push_back(node2);
node2->neighbors.push_back(node1); // 循环引用——可正确处理!
auto bytes = fory.serialize(node1).value();
// 不会栈溢出、不会重复写入——循环结构可被完整保留
auto decoded = fory.deserialize<std::shared_ptr<Node>>(bytes).value();
这让 Fory 非常适合图数据库、实体组件系统,以及任何含双向关系的领域模型。
Schema 演进
在微服务部署中,各服务通常独立迭代。例如用户服务新版本新增 phone 字段时,旧消费者可能仍在线。如果没有 Schema 演进支持,就会被迫做协调式的“大爆炸发布”。Apache Fory 的 兼容模式 可以彻底解除这个约束:
// 版本 1
struct UserV1 { std::string name; int32_t age; };
FORY_STRUCT(UserV1, name, age);
// 版本 2——独立新增字段
struct UserV2 { std::string name; int32_t age; std::string email; };
FORY_STRUCT(UserV2, name, age, email);
auto fory_v1 = Fory::builder().compatible(true).xlang(true).build();
auto fory_v2 = Fory::builder().compatible(true).xlang(true).build();
fory_v1.register_struct<UserV1>(100);
fory_v2.register_struct<UserV2>(100); // 使用同一 type ID 才能实现演进
auto bytes = fory_v1.serialize(UserV1{"Alice", 30}).value();
auto v2 = fory_v2.deserialize<UserV2>(bytes).value();
assert(v2.name == "Alice" && v2.email == ""); // 缺失字段将使用默认值
在兼容模式下,字段按名称匹配而不是按位置匹配。缺失的新字段会回落到 C++ 默认值,被删除的字段会被安全跳过。这样就能实现滚动升级与独立服务发布,而不会触发序列化错误。
行式格式:零拷贝分析
除了对象图序列化,Apache Fory C++ 还提供面向分析负载的 行式二进制格式。行式格式采用连续内存布局,包含空值位图、基础类型定长槽位,以及字符串/嵌套对象的变长区域。这带来 按索引 O(1) 随机字段访问——你可以从大 struct 中直接读取某个字段,无需反序列化全部数据。
这在数据管道和 OLAP 负载中非常有价值,因为单条记录往往只查询少数字段:
#include "fory/encoder/row_encoder.h"
using namespace fory::row::encoder;
struct SensorReading {
int32_t sensor_id; double temperature; std::string location;
FORY_STRUCT(SensorReading, sensor_id, temperature, location);
};
RowEncoder<SensorReading> encoder;
encoder.encode({42, 23.5, "rack-B"});
auto row = encoder.get_writer().to_row();
// 可按 O(1) 读取任意字段——无需反序列化未使用字段
int32_t id = row->get_int32(0);
double temp = row->get_double(1);
auto loc = row->get_string(2);
如果要在已有缓冲区上做零拷贝访问(例如内存映射文件或网络接收缓冲区),Fory 可以让 Row 直接指向那段内存而不做拷贝:
auto src = encoder.get_writer().to_row();
fory::row::Row view(src->schema());
view.point_to(src->buffer(), src->base_offset(), src->size_bytes()); // 零拷贝视图
int32_t id = view.get_int32(0); // 直接从原始缓冲区读取
建议:分析、OLAP 风格与部分字段读取场景使用行式格式;需要完整对象往返(含引用与多态)时使用对象图序列化。
安装
Fory C++ 需要兼容 C++17 的编译器(GCC 7+、Clang 5+、MSVC 2017+),并同时支持 CMake 与 Bazel。
CMake (FetchContent)
最简单的接入方式是使用 CMake 的 FetchContent 模块,在你的项目构建过程中直接拉取并编译 Fory:
cmake_minimum_required(VERSION 3.16)
project(my_project LANGUAGES CXX)
set(CMAKE_CXX_STANDARD 17)
include(FetchContent)
FetchContent_Declare(fory
GIT_REPOSITORY https://github.com/apache/fory.git
GIT_TAG v0.15.0
SOURCE_SUBDIR cpp)
FetchContent_MakeAvailable(fory)
add_executable(my_app main.cc)
target_link_libraries(my_app PRIVATE fory::serialization)
Bazel
对于 Bazel 项目,可将 Fory 作为 module dependency 引入:
bazel_dep(name = "fory", version = "0.15.0")
git_override(module_name = "fory",
remote = "https://github.com/apache/fory.git",
commit = "v0.15.0")
cc_binary(name = "my_app", srcs = ["main.cc"],
deps = ["@fory//cpp/fory/serialization:fory_serialization"])
原生序列化
如果是纯 C++ 应用且不需要跨语言能力,关闭 xlang 可以得到更紧凑的二进制编码(因为不再输出跨语言类型元数据),这也是最快路径:
auto fory = Fory::builder()
.xlang(false) // 原生 C++ 模式——编码更紧凑
.track_ref(false) // 若无共享/循环引用可关闭
.build();
fory.register_struct<Address>(1);
fory.register_struct<Person>(2);
// 序列化
auto result = fory.serialize(person);
if (!result.ok()) { std::cerr << result.error().to_string(); return 1; }
std::vector<uint8_t> bytes = std::move(result).value();
// 反序列化
auto decoded = fory.deserialize<Person>(bytes);
assert(decoded.ok() && person == decoded.value());
FORY_STRUCT 还能很好覆盖生产代码里常见的几个 C++ 模式:
// 私有字段——将宏放在 public: 区域
class Secure {
int32_t secret_; std::string token_;
public:
FORY_STRUCT(Secure, secret_, token_);
};
// 继承——`FORY_BASE` 包含基类字段
struct Derived : Base {
std::string extra;
FORY_STRUCT(Derived, FORY_BASE(Base), extra);
};
// 外部/第三方类型——在 namespace 作用域使用(仅限 public 字段)
namespace ext { struct Coord { double lat, lon; }; }
FORY_STRUCT(ext::Coord, lat, lon);
错误处理
Fory 所有操作都返回 Result<T, Error>,让错误处理清晰、可组合。对于需要向上传播错误的函数,FORY_TRY 宏提供了精炼的提前返回模式:
// 方式 1:条件判断
auto r = fory.serialize(obj);
if (r.ok()) { auto bytes = std::move(r).value(); }
else { std::cerr << r.error().to_string(); }
// 方式 2:使用 `FORY_TRY` 宏提前返回
FORY_TRY(bytes, fory.serialize(obj));
// 可直接使用 bytes——错误会自动向上传播
线程安全
Fory 提供两种线程模型。选择依据是:你的序列化能力是集中管理(共享实例)还是分散在线程内部:
// 单线程(最快)——每个线程一个实例,无同步开销
auto fory = Fory::builder().build();
// 线程安全——通过内部实例池跨线程共享
auto fory = Fory::builder().build_thread_safe();
fory.register_struct<MyType>(1); // 共享前先注册全部类型
std::thread t([&]() { fory.serialize(obj); }); // 可安全并发调用
跨语言序列化
不使用 IDL
当你能同时控制通信双方,并可手工协调类型定义时,最简方式是在各语言中注册一致的数字类型 ID。这不需要额外工具,适合小型、稳定 Schema:
// C++
auto fory = Fory::builder().xlang(true).build();
fory.register_struct<Order>(201);
auto bytes = fory.serialize(order).value();
// Java——同一二进制格式、同一 type ID
Fory fory = Fory.builder().withLanguage(Language.XLANG).build();
fory.register(Order.class, 201);
Order order = (Order) fory.deserialize(bytes);
# Python——同一二进制格式、同一 type ID
fory = pyfory.Fory(xlang=True)
fory.register(Order, type_id=201)
order = fory.deserialize(data)
字段匹配:在跨语言模式下,字段名会规范化为 snake_case,并按该规范名称匹配。字段顺序遵循 Fory 的 xlang 字段排序规则(并非简单字母序),因此跨语言命名语义要保持一致。
使用 Fory Schema IDL Compiler
随着 Schema 规模扩大、服务和团队增多,手工维护五种语言中的字段名、类型 ID 与类型定义会越来越容易出错。Fory Schema IDL Compiler(foryc)通过“单一 .fdl 定义,多语言自动生成”的方式解决这一问题。生成代码包含类型化访问器、序列化宏、注册辅助函数,以及 to_bytes()/from_bytes() 辅助函数——你无需再手写任何序列化胶水代码。
1. 安装编译器
pip install fory-compiler
foryc --help
2. 编写 Schema(ecommerce.fdl)
Fory IDL 语法简洁,且刻意贴近 protobuf,学习成本很低。optional、ref、list 等字段修饰符会直接映射到地道的 C++ 类型:
package ecommerce;
enum OrderStatus {
PENDING = 0; CONFIRMED = 1; SHIPPED = 2; DELIVERED = 3;
}
message Address {
string street = 1; string city = 2; string country = 3;
}
message Customer {
string id = 1;
string name = 2;
optional string email = 3; // Nullable: maps to std::optional<std::string>
optional Address address = 4;
}
message OrderItem {
string sku = 1;
int32 quantity = 2;
float64 unit_price = 3;
}
// Discount 既可以是固定金额,也可以是百分比——用 union 建模
message FixedDiscount { float64 amount = 1; }
message PercentDiscount { float64 percentage = 1; }
// union 在 C++ 中映射为 std::variant<FixedDiscount, PercentDiscount>
union Discount {
FixedDiscount fixed = 1;
PercentDiscount percent = 2;
}
message Order {
string order_id = 1;
ref Customer customer = 2; // ref:std::shared_ptr + 引用跟踪
list<OrderItem> items = 3; // list:std::vector<OrderItem>
OrderStatus status = 4;
float64 total = 5;
optional string notes = 6;
timestamp created_at = 7;
optional Discount discount = 8; // 可选 union 字段
}
IDL 类型系统与原生 C++ 构造的映射非常直接。union 是一等公民,会在 C++ 中生成基于 std::variant 的包装类,并提供类型化分支访问器(如 is_fixed()、as_fixed())以及 visit() 方法。下表是字段修饰符及其 C++ 对应关系:
| 字段修饰符 | C++ 类型 | 用途 |
|---|---|---|
optional T | std::optional<T> | 可空字段 |
ref T | std::shared_ptr<T> | 共享/循环引用 |
ref(weak=true) T | fory::serialization::SharedWeak<T> | 弱引用(用于打断循环) |
list<T> | std::vector<T> | 有序列表 |
map<K,V> | std::map<K,V> | 键值映射 |
3. 生成代码
foryc 会为 C++ 每个 Schema 生成一个头文件,并为其他目标语言生成对应文件。所有生成文件都会使用同一套由 package 与类型名推导出的类型 ID,从而在无需手工协调的前提下保证二进制兼容:
# 在 ./generated 下直接生成 C++ 头文件
foryc ecommerce.fdl --cpp_out ./generated
# 使用显式输出目录生成多语言代码
foryc ecommerce.fdl --cpp_out ./generated --java_out ./java/src/main/java --python_out ./python/gen --go_out ./go/gen --rust_out ./rust/gen
C++ 输出结构是:每个 Schema 文件在 --cpp_out 指定目录下生成一个头文件。比如 --cpp_out ./generated 会得到 generated/ecommerce.h。该头文件内已包含 ecommerce:: namespace 下的全部类型,并预置 FORY_STRUCT 宏与 register_types() 辅助函数。
4. 使用生成的 C++ 代码
生成的头文件提供带类型化访问器的 final 类,以及 to_bytes()/from_bytes() 辅助函数。无需手动创建 Fory 实例,辅助函数会在内部完成管理:
#include "generated/ecommerce.h"
ecommerce::Order order;
order.set_order_id("ORD-2025-001");
order.mutable_customer()->set_name("Alice");
order.set_status(ecommerce::OrderStatus::CONFIRMED);
order.set_total(159.98);
// `to_bytes()`/`from_bytes()` 由工具生成——无需手写 Fory 样板代码
auto bytes = order.to_bytes().value();
auto restored = ecommerce::Order::from_bytes(bytes).value();
assert(restored.order_id() == "ORD-2025-001");
由于生成的 Java、Python、Go 代码使用相同类型 ID,C++ to_bytes() 写出的字节可以被 Java fromBytes() 或 Python from_bytes() 直接读入,开箱即用,不需要额外配置。
支持的类型
Apache Fory C++ 支持覆盖常见 C++ 数据结构与跨语言基础类型的完整类型集:
| 类别 | C++ 类型 |
|---|---|
| 基础类型 | bool, int8_t…int64_t, uint8_t…uint64_t, float, double |
| 字符串 | std::string, std::string_view, std::u16string |
| 集合 | std::vector<T>, std::set<T>, std::unordered_set<T>, std::map<K,V>, std::unordered_map<K,V> |
| 可选/联合类型 | std::optional<T>, std::variant<Ts...> |
| 智能指针 | std::shared_ptr<T>(引用跟踪 + 多态)、std::unique_ptr<T>、fory::serialization::SharedWeak<T> |
| 时间类型 | std::chrono::nanoseconds, fory::serialization::Timestamp, fory::serialization::Date |
| 枚举 | 作用域/非作用域枚举;非连续值请使用 FORY_ENUM |
| 用户结构体 | 所有通过 FORY_STRUCT 标注的类型 |
集合元素与映射值类型都支持任意层级嵌套,包括 struct、智能指针与 std::optional。
配置参考
Fory 实例通过链式 builder API 构造。所有配置都有合理默认值,大多数场景只需设置 1~2 项:
auto fory = Fory::builder()
.xlang(true) // 跨语言二进制协议(默认:true)
.compatible(true) // Schema 演进/兼容模式(默认:false)
.track_ref(true) // 共享/循环引用跟踪(默认:true)
.max_dyn_depth(10) // 多态嵌套最大深度(默认:5)
.check_struct_version(true) // 反序列化时校验结构体哈希(默认:false)
.build(); // 单线程;多线程请使用 build_thread_safe()
调优建议:当 Schema 变更可协调(同版本二进制同步发布)时,关闭 compatible 可获得最大吞吐;若数据是纯值类型且不存在共享/循环,关闭 track_ref 可省去每对象引用记账;仅 C++ 部署下使用 xlang(false) 可进一步压缩二进制编码。
性能基准
Apache Fory 在多种数据形态上都表现出色。得益于编译期代码生成、可变长整数编码,以及精心设计的二进制协议,相比文本格式有显著优势,相比 Protocol Buffers 也有很强竞争力。在当前 C++ 基准报告中,Fory 相对 Protobuf 的吞吐提升范围约为 1.1x ~ 12.2x(取决于负载与操作类型):
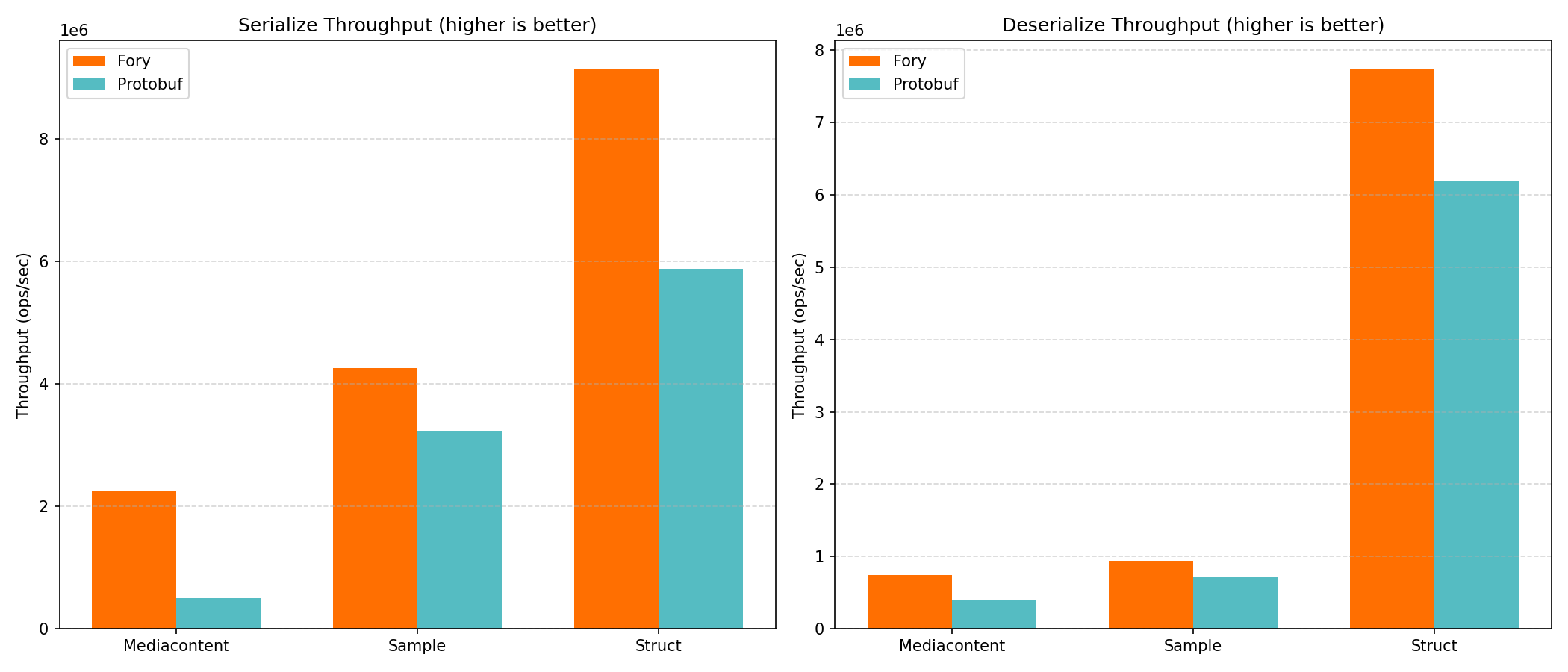
C++ 实现与 Java 实现的相对加速趋势基本一致。二者共享同一套二进制协议设计,而 C++ 序列化代码在编译期生成(避免 JIT 预热成本),因此在时延敏感负载中通常具备同等甚至更优表现。
序列化数据大小(bytes)
| 数据类型 | Fory | Protobuf |
|---|---|---|
| Struct | 58 | 61 |
| Sample | 446 | 375 |
| MediaContent | 365 | 301 |
| StructList | 184 | 315 |
| SampleList | 1980 | 1890 |
| MediaContentList | 1535 | 1520 |
总结
Apache Fory C++ 将其他 C++ 序列化库很难“一次性同时做到”的能力,打包成了完整且一致的工程方案:
- 性能:基于模板的编译期代码生成消除了运行时反射开销;高效二进制协议同时优化序列化体积与 CPU 成本
- 跨语言:同一二进制格式原生支持 Java、Python、Go、Rust、JavaScript
- 原生 C++ 惯用法:
std::shared_ptr、std::optional、std::variant、fory::serialization::SharedWeak均可自然处理 - 生产级特性:多态、循环引用、Schema 演进、线程安全开箱即用
- Schema 优先选项:Fory IDL Compiler 基于单一
.fdl定义生成多语言地道代码,不再手工同步各代码库 type ID
无论你在构建高性能游戏服务器、多语言微服务后端、实时分析管道,还是需要序列化复杂领域模型的嵌入式系统,Apache Fory C++ 都能覆盖。
快速开始:
git clone https://github.com/apache/fory.git
cd fory/examples/cpp/hello_world
cmake -B build -DCMAKE_BUILD_TYPE=Release && cmake --build build
./build/hello_world
文档:
- C++ 序列化指南: fory.apache.org/docs/guide/cpp
- Fory Schema IDL 编译器: fory.apache.org/docs/compiler
- Xlang 序列化规范: fory.apache.org/docs/specification
社区:
- GitHub: apache/fory
- Slack: 加入我们的社区
- 许可证:Apache License 2.0